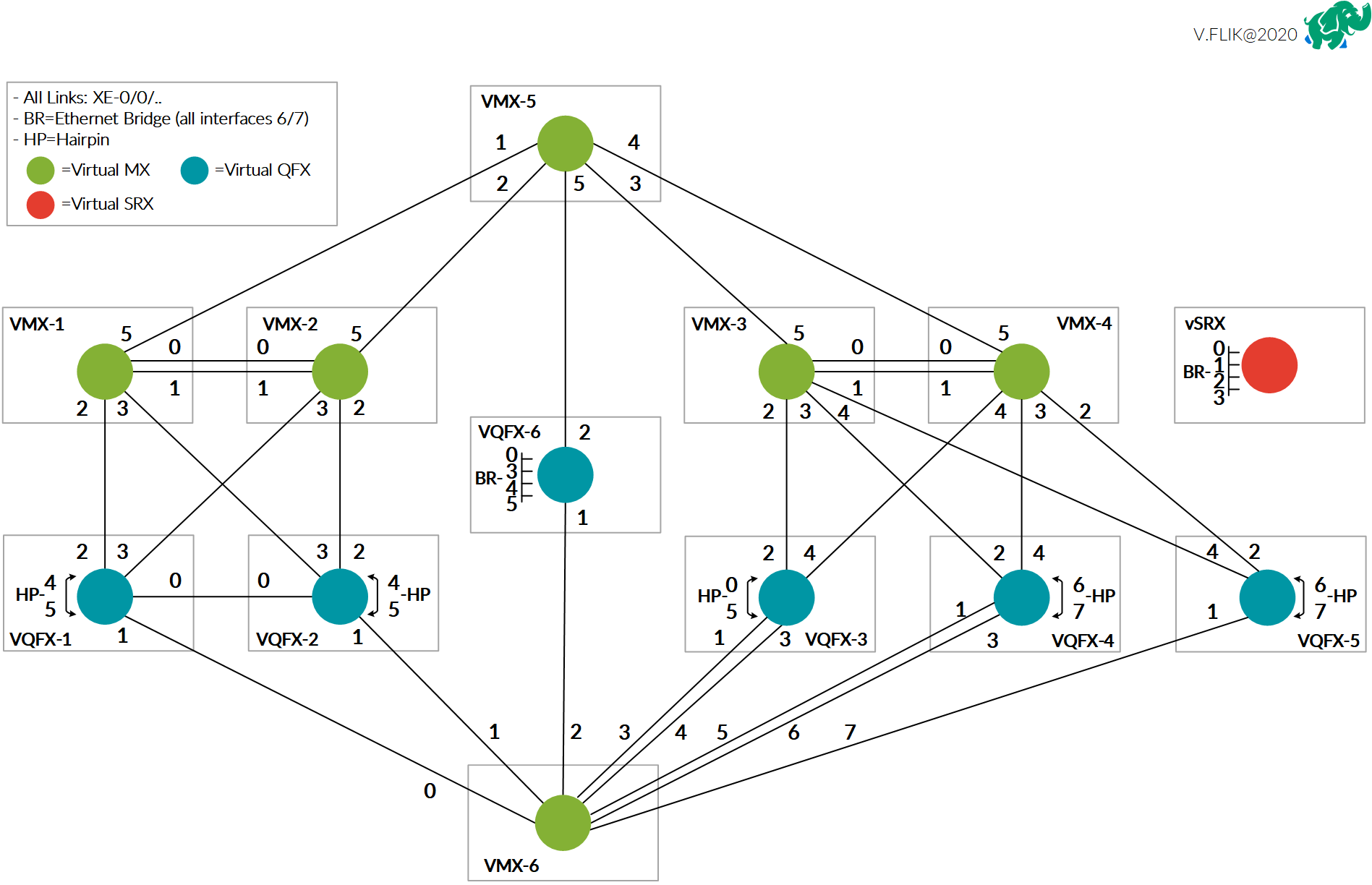
After having some feedback regarding my previous post on running the JNCIE-DC self-study workbook in EVE-NG. I wanted to share some of the most common questions I personally experienced while using the lab and general things to be aware of and some tips!
I also ran into some aspects of going through the workbook that also would change some small decisions I made when deploying the lab.
vQFX version
The more recent versions of the vQFX are experiencing some issues inside EVE-NG. Sometimes the vQFX RE comes up in the line card role. This is an aspect of Virtual Chassis technology, which is not supported on the vQFX. When the system is in line card role, it means it does not maintain an editable configuration as that would be done by switches in the VC with Routing Engine role.
I am currently running vQFX with Junos 17.4R1.16 and that is very stable at the moment. In the JNCIE-DC lab environment a much older version is used, so for feature parity is not an issue and stability matters most right now. So stay away from the more recent Junos 18.x and Junos 19.x vQFX versions to ensure a stable device. I have gotten them to work plenty of times, but it’s not stable enough and I don’t want the lab to be in my way when I’m studying for an exam.
vQFX data-plane / em1 interface
The vQFX is supported to run in 2 different versions. ‘light’ mode and ‘full’ mode. Light mode means that you only boot up a routing-engine image. This deployment will only support any layer 3 IP services to, for example, test IP Fabric use cases. Your interfaces will all map to ’emX’ ones and will not be shown as xe-0/0/X in the system. To utilise the virtual PFE, the full potential of the vQFX and the ability to run layer 2 bridging and EVPN services you will need the ‘full’ version which requires to deploy a second VM for each vQFX which will run a virtualised version of the Q5 PFE.
It’s key to have the connection in place between the vRE and vPFE. This is done by making a connection on port em1 on the vRE and port int on the vPFE. On the vMX the connection is similar, but once made in EVE-NG the configuration is not visible in Junos. On the vQFX the IP addressing between these 2 VMs is required to be in the configuration, otherwise you will lose the connectivity to the vPFE and that will result in losing the xe-0/0/X interfaces being visible from the CLI.
It’s easy to miss this out, because the vQFX boots up with a full list of interfaces with regular ethernet-switching configuration. During your labbing it’s easiest to delete the entire interface stanza before starting, but by doing this you will also delete the em1 interface which handles this vRE to vPFE communication and needs to be configured with the IP address 169.254.0.2/24. The em0 interface is similar to the fxp0 interface on vMX and that is your direct connection to the virtual RE or the out of band management interface.
When I start working on a new vQFX I immediately delete all interfaces, but make sure you put the em1 configuration back! Along with maybe your management subnet configuration!
delete interfaces
set interfaces em1 unit 0 family inet address 169.254.0.2/24
Management subnet
The JNCIE-DC workbooks consists of many chapters and many parts within those chapters. For each part in a chapter there are separate starting/initial configurations as they typically do not build on top of each other. This means you will be loading a lot of new configurations during your labbing.
Copying and pasting configurations over the virtual console connection that EVE-NG sets up to the serial port is typically not the best idea. Unless you delay the speed that your terminal emulator pastes information in the window.
To also get the best connection to your devices. I would recommend using the out of band management interfaces (em0 on vQFX and fxp0 on vMX) to connect to the devices. It gives me the most stable connection to the devices and does not mind pasting in big chunks of configuration.
The initial configurations of the JNCIE-DC workbook are set-up with an out of band management subnet of 10.10.20.0/24. I’m using a different subnet for my lab devices VLAN, so when I open a new initial configuration I have to do a find-replace action. You could also make your life easier by using the subnet in our lab if that’s an option!
The SSH access to the devices is really helpful again to quickly load configurations, which I not only use for the initial configs, but also for copying and pasting parts of config between devices during the labs.
Initial configurations
Take good care of loading initial configs for each part. EVE-NG is not the best at managing this on Juniper devices, because it expects a device to be logged in. Which a Juniper device never is. You always end up in a log-in prompt.
I found it too much of a hassle to work on updating the configs, as each chapter has multiple initial configs for the various parts of the chapter. This means you will be loading and replacing a lot of configurations during your work in the book.
I find it useful to save my final configs for each part as well. Some people like to log all the command outputs to a text file, but I feel that’s a bit much when you’re working on a lot of devices and are typing a lot. Saving final configs does help in checking your answers in the book at a later time. I typically work on it in the evening and then only have time to finish a few parts of a chapter. The next day I’ll go back and verify my work in the book and review my configs in text files.
When loading in the initial configurations. It’s important to keep in mind your management subnet on the fxp0 and em0 interfaces, so that you don’t lose connectivity after a commit!
Loading in a brand new configuration on a Junos device is fortunately very easy. Just use the load override terminal command and paste in your new config. After a commit your device has a complete new identity!
Copy/Paste between devices
When working through the chapters. You will find that a lot of configuration will be similar on multiple devices. Especially routing protocol knobs such as authentication or policies. I find it very useful to do configuration on one device and then using a show | compare to verify. Copying the output of that to a new device works really well by using the load patch terminal on the other device to load in the differences.
I also find it very useful to have a text editor open next to me. I use Sublime Text 3 with the Junos plugin so it highlights the syntax. Especially configuring a lot of BGP peers (like in an IP fabric setup), it helps keeping the configuration consistent and only a few IP addresses will change between devices. Being able to quickly change this and then copying it over to the other device saves a lot of time and potential errors!
Reconfigurations
As mentioned before, the parts within the chapter do not build on each other. This means you have to wipe and reconfigure the devices before moving to another part of the workbook. I’ve experienced a few times that after I wiped the config and reconfigured the device for the next part (load override) that the devices can behave strange. Which would result in not having IP connectivity on links. The problem is that you will be configuring something and you want to verify that what you did is correct. So if verification fails, it makes you doubt your own config. In the case of reconfiguring the devices multiple times, I’ve seen it happen that sometimes the config is not correctly applied in the vPFEs. This means that the configuration does not reflect the actual implementation in the device. To get this fixed a full reboot of both the vRE and vPFE would solve this!
Flapping peers
Again similar to the previous point. I reset the configurations to a new part of the chapter and after verifying IP connectivity I thought everything was OK, but after configuring BGP. I experienced weird issues with flapping peers. Every 1 to 2 minutes all my BGP peers would suddenly reset. Even after a reboot of the virtual appliances!
I abandoned troubleshooting initially, because it was already late at night. I powered off my server and powered it back on again the next day. After the appliances were all running again. The problem was gone and my config hadn’t changed at all! So even if a reboot doesn’t fix your issue try to close the lab and re-open it in EVE-NG or reboot your entire server to fix issues of which you are (almost) certain they are not related to your configs!
EVE-NG Client Pack
As a few final thoughts I’d like to highlight some of the excellent features that EVE-NG brings to the table. The first I’d like to mention is the client pack that EVE-NG offers for all desktop operating systems. Logging in on the native console (not the HTML5 one, which I only use when I’m not connected of EVE-NG offers you the ability to open console sessions to your devices using your favorite terminal emulator. Which to me personally is iTerm2 on macOS and SecureCRT on Windows.
On iTerm2 ensure you select the setting to have iTerm2 be the default ssh:// url handler in the profile settings.
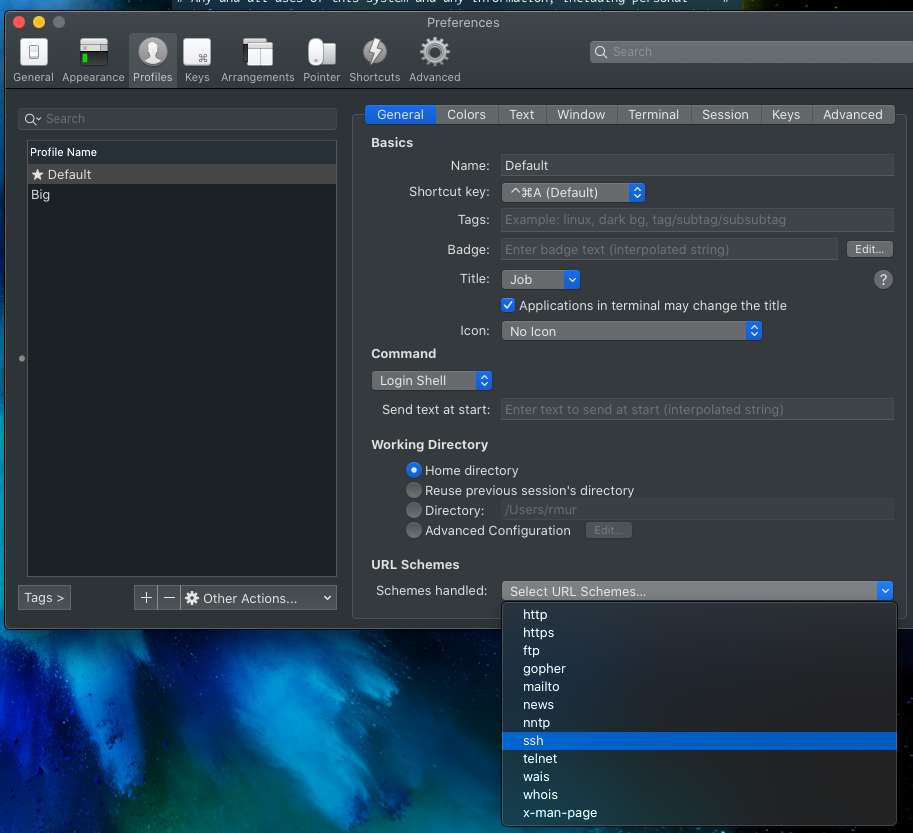
On Windows if you want SecureCRT to be used as default app to open console windows. The EVE-NG Client Pack installs scripts to make this easy. Go to C:\Program Files (x86)\EVE-NG\ and open the .reg file that reflects either the 32-bit or 64-bit version of SecureCRT which is abbreviated with sCRT. After running the reg file, SecureCRT should open automatically when opening console windows. If it does not search in your start menu for Default Apps, then go to Choose default apps by protocol and select SecureCRT as the default application for the TELNET protocol.
By default on Windows each session you open on EVE-NG will open a new window of SecureCRT. Where most people will prefer new tabs. To change this go into your SecureCRT config directory which is usually found under: C:\Users\<username>\AppData\Roaming\VanDyke\Config and find the Global.ini file and change the following line:
D:"Single Instance"=00000000
and update to
D:"Single Instance"=00000001
Now all new windows will open as tabs in the same window.
EVE-NG Miscellaneous
Depending on your server the bootup times it could take a very long time to boot all the virtual appliances. Sometimes it could feel that they are stuck, but be patient is the only solution to that (or faster CPU’s of course 🙂
Finally, make sure you update your EVE-NG installation using standard apt commands. Recently a vulnerability was discovered in one of the modules that EVE-NG uses so always make sure you are running an up to date installation. Fortunately that’s very easy to do!
Happy labbing!!