During the implementation of using my own public IP space on my home server I ran into a weird issue of not being able to pass traffic between hosts on either side of the VPN. After investigation it seems to be a combination of factors by using GRE tunneling, a policy based site-to-site VPN rather than a route-based site-to-site VPN and the (v)SRX platform. Please note that I only tested this on the Virtual SRX platform, not on physical appliances. I did test in multiple releases of Junos, but found that it affects all that I tested (latest I tested is Junos 20.1R1.11).
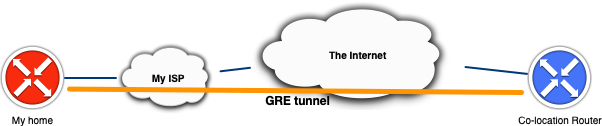
As described in the previous blog post regarding running own public IP space in your home lab behind a consumer internet connection. I run a GRE tunnel to a router that is connected via multiple peering and transit connections which allows me to advertise my own AS and IP prefixes. Then going across the internet I want to run a site-to-site VPN towards another location where back-ups of my homelab are stored.
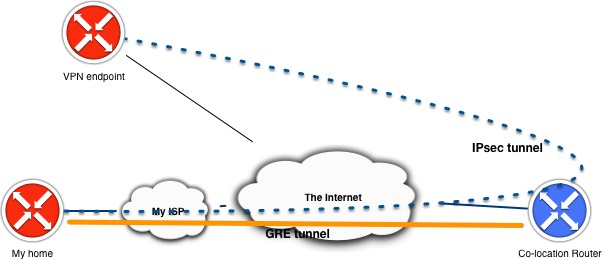
IPsec over GRE or GRE over IPsec
The 2 variants seem to be used interchangeably if you search for this deployment online, but my use case was very much the first option. I’m running a site-to-site VPN over a GRE tunnel across the internet towards another VPN endpoint. The latter option is a much more deployed option in real life as it enables the user to support other types of network traffic that are traditionally not possible with a IPsec VPN like supporting multicast or MPLS traffic.
The design I’m trying to implement is not very typical and (should) not (be) found in production networks (as it’s really a workaround). What I’m trying to say is that when GRE and IPsec are typically deployed end-to-end it is between the same endpoints. In my case the GRE tunnel terminates before the IPsec VPN endpoint.
Initial configuration
Let’s first set a baseline in a lab environment to test this out. I’m using my lab server running EVE-NG to set-up a lab with 2 vSRX firewalls at my Home and my Remote site. Then a vMX router simulating my ISP (just a transit for GRE traffic), a vMX router terminating my GRE tunnel and advertising the public IP prefix. Finally 2 Docker containers simulating end hosts to generate some test pings that are in the LAN subnets behind both vSRX firewalls. To keep the blog readable, full configurations are not shown, but only relevant parts.
The set-up is as shown in the diagram
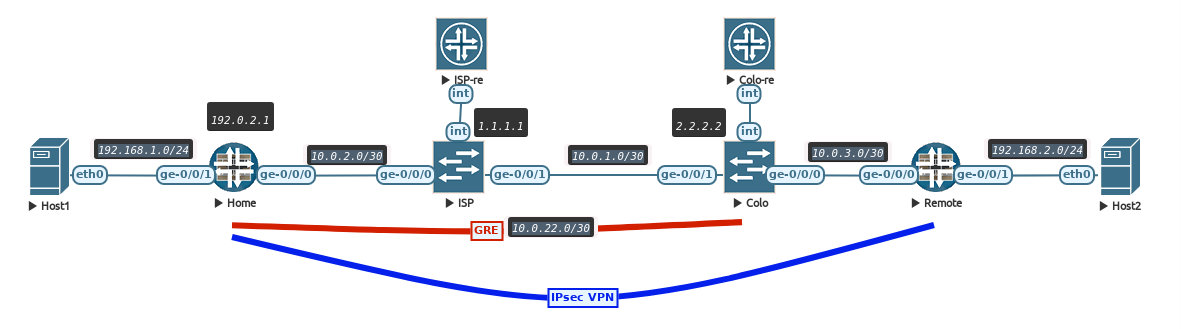
The ISP and COLO routers have full reachability with each other using OSPF so the loopbacks are reachable as if they are internet hosts. The GRE tunnel is set-up between the Home SRX and COLO router and, just like in the previous blog, using BGP to exchange a public IP prefix so my home router is reachable via that. The Home SRX has a Loopback IP of 192.0.2.1.
interfaces {
/* ISP Uplink */
ge-0/0/0 {
unit 0 {
family inet {
address 10.0.2.2/30;
}
}
}
/* GRE to COLO router */
gr-0/0/0 {
unit 0 {
clear-dont-fragment-bit;
tunnel {
source 10.0.2.2;
destination 2.2.2.2;
allow-fragmentation;
}
family inet {
mtu 1476;
address 10.0.22.2/30;
}
}
}
/* Home LAN */
ge-0/0/1 {
unit 0 {
family inet {
address 192.168.1.1/24;
}
}
}
/* Public IP address */
lo0 {
unit 0 {
family inet {
address 192.0.2.1/32;
}
}
}
}
protocols {
bgp {
group COLO {
type external;
/* Export public IP prefix */
export colo-export;
peer-as 65000;
neighbor 10.0.22.1;
}
}
}
routing-options {
static {
route 2.2.2.2/32 next-hop 10.0.2.1;
route 192.0.2.0/24 discard;
}
router-id 3.3.3.3;
autonomous-system 65001;
}As shown above in the static routes. The Home SRX only knows how to reach the COLO router via the regular ISP uplink and will rely on a default route imported via BGP over the GRE tunnel for all other destinations.
root@Home> show route
inet.0: 10 destinations, 10 routes (10 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
0.0.0.0/0 *[BGP/170] 05:13:34, MED 0, localpref 100
AS path: 65000 I, validation-state: unverified
> to 10.0.22.1 via gr-0/0/0.0
2.2.2.2/32 *[Static/5] 05:13:37
> to 10.0.2.1 via ge-0/0/0.0
10.0.2.0/30 *[Direct/0] 05:13:37
> via ge-0/0/0.0
10.0.2.2/32 *[Local/0] 05:13:37
Local via ge-0/0/0.0
10.0.22.0/30 *[Direct/0] 05:13:37
> via gr-0/0/0.0
10.0.22.2/32 *[Local/0] 05:13:37
Local via gr-0/0/0.0
192.0.2.0/24 *[Static/5] 05:14:53
Discard
192.0.2.1/32 *[Direct/0] 05:14:53
> via lo0.0
192.168.1.0/24 *[Direct/0] 05:13:37
> via ge-0/0/1.0
192.168.1.1/32 *[Local/0] 05:13:37
Local via ge-0/0/1.0The host containers on the home and remote LAN subnets are now able to reach the internet via a simple source NAT configuration. On the remote subnet this is done via the interface IP address and on the home subnet this is done by using the public IP address (192.0.2.1). Both hosts are able to reach the loopback IP of the ISP router (remember, the Home SRX is directly connected, but only know how to reach it via the GRE tunnel received default route over BGP).
host1:/# ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=62 time=4.17 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=62 time=2.83 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=62 time=3.18 ms
Host2:/# ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=62 time=12.8 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=62 time=2.02 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=62 time=1.57 ms
IPsec configuration
As this set-up is replicating my own home set-up. I am using a policy based VPN, because the remote side is using a device which does not support a route based VPN (using an st0 interface on Junos or similar on other vendors).
The most important part in the config is the exclusion of the traffic dedicated for the IPsec VPN (192.168.1.0/24 destined for 192.168.2.0/24) of the NAT rule, as I just want the 2 subnets to communicate directly without translation.
Second is the policy part, where the policy is used to trigger the encapsulation of traffic in ESP packets for the traffic between the 2 subnets.
security {
ike {
proposal ike-vpnProposal {
authentication-method pre-shared-keys;
dh-group group5;
authentication-algorithm sha1;
encryblogion-algorithm aes-128-cbc;
lifetime-seconds 28800;
}
policy ike-vpnPolicy {
mode main;
proposals ike-vpnProposal;
pre-shared-key ascii-text blablabla;
}
gateway gw-blog {
ike-policy ike-vpnPolicy;
address 10.0.3.2;
external-interface lo0.0;
local-address 192.0.2.1;
}
}
ipsec {
proposal ipsec-vpnProposal {
protocol esp;
authentication-algorithm hmac-sha1-96;
encryblogion-algorithm aes-128-cbc;
lifetime-seconds 3600;
}
policy ipsec-vpnPolicy {
perfect-forward-secrecy {
keys group5;
}
proposals ipsec-vpnProposal;
}
vpn vpn-blog {
ike {
gateway gw-blog;
ipsec-policy ipsec-vpnPolicy;
}
establish-tunnels immediately;
}
}
address-book {
untrust {
address remote-network 192.168.2.0/24;
attach {
zone untrust;
}
}
trust {
address home-network 192.168.1.0/24;
attach {
zone trust;
}
}
}
nat {
source {
pool internet {
address {
192.0.2.1/32;
}
}
rule-set trust-to-untrust {
from zone trust;
to zone untrust;
rule vpn {
match {
source-address 192.168.1.0/24;
destination-address 192.168.2.0/24;
}
then {
source-nat {
off;
}
}
}
rule all {
match {
source-address 0.0.0.0/0;
}
then {
source-nat {
pool {
internet;
}
}
}
}
}
}
}
policies {
from-zone trust to-zone untrust {
policy vpn2 {
match {
source-address home-network;
destination-address remote-network;
application any;
}
then {
permit {
tunnel {
ipsec-vpn vpn-blog;
pair-policy vpn;
}
}
}
}
policy permit-all {
match {
source-address any;
destination-address any;
application any;
}
then {
permit;
}
}
}
from-zone untrust to-zone trust {
policy vpn {
match {
source-address remote-network;
destination-address home-network;
application any;
}
then {
permit {
tunnel {
ipsec-vpn vpn-blog;
pair-policy vpn2;
}
}
}
}
}
}
}Now the VPN is configured and active we can test reachability
root@Home> show security ipsec security-associations
Total active tunnels: 1 Total Ipsec sas: 1
ID Algorithm SPI Life:sec/kb Mon lsys Port Gateway
<2 ESP:aes-cbc-128/sha1 7df48801 2520/ unlim - root 500 10.0.3.2
>2 ESP:aes-cbc-128/sha1 eea8273a 2520/ unlim - root 500 10.0.3.2 The behavior seen is very strange. The Home LAN host cannot access the Remote LAN host, but from the Remote to Home all seems to work fine!
host1:/# ping 192.168.2.2
PING 192.168.2.2 (192.168.2.2) 56(84) bytes of data.
^C
--- 192.168.2.2 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2044ms
Host2:/# ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=62 time=3.27 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=62 time=3.36 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=62 time=3.67 ms
Weird IPsec over GRE issue
The problem seems to be with how the SRX policy engine encapsulates traffic. The ‘double encapsulation’ of both ESP and GRE does not seem to be working when the GRE and ESP endpoint are not the same IP address. In this case the GRE tunnel terminates well before the IPsec endpoint.
In the session flow output, everything seems to be okay with next-hop correctly showing the GRE tunnel, but no traffic is showing up on the other side.
root@Home> show security flow session
Session ID: 162, Policy name: vpn2/4, Timeout: 58, Valid
In: 192.168.1.2/152 --> 192.168.2.2/1;icmp, Conn Tag: 0x0, If: ge-0/0/1.0, Pkts: 1, Bytes: 84,
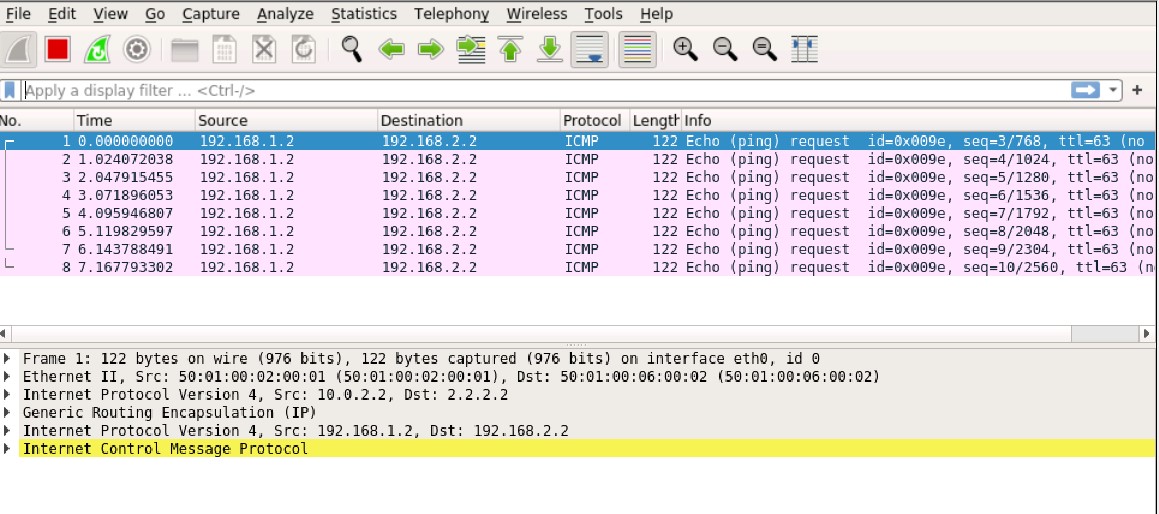
Out: 192.168.2.2/1 --> 192.168.1.2/152;icmp, Conn Tag: 0x0, If: gr-0/0/0.0, Pkts: 0, Bytes: 0, This is clearly seen in a packet capture on the Home SRX ISP uplink interface. Only GRE packets are seen, but they are unencrypted!
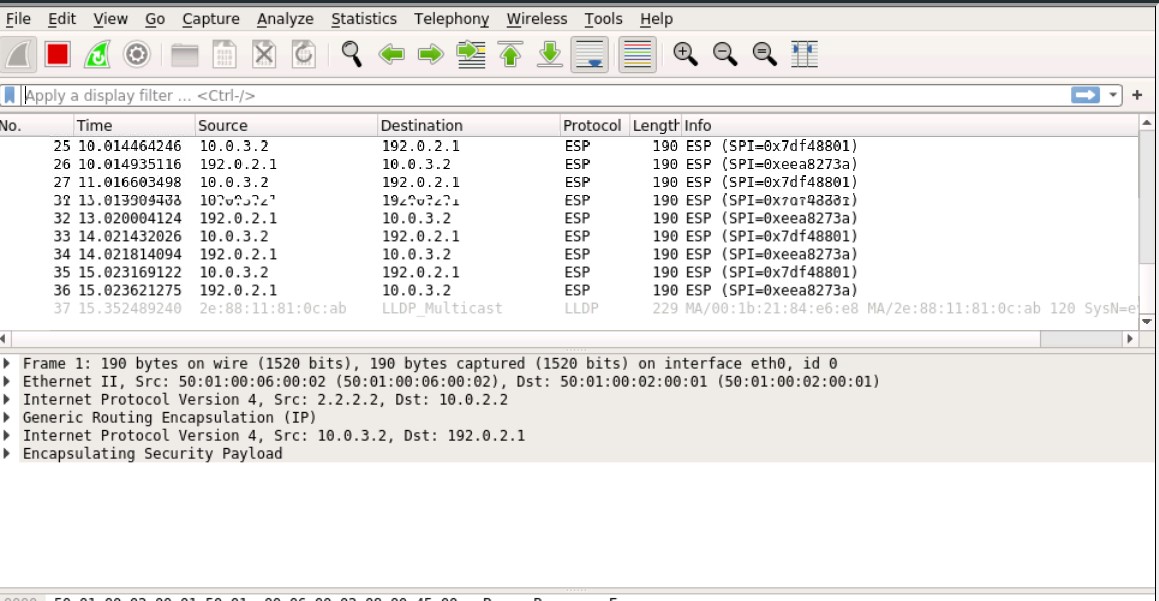
When the ping is initiated from the remote side, the ping is working fine. Even the return traffic is correctly encapsulated in the IPsec tunnel with ESP.
Solution(s)
The limitation seems to be the combination of using a policy based VPN with a GRE tunnel as underlay that does not terminate on the same device/IP as the IPsec tunnel. Again the use case for this is limited and I would not see a lot of people running into this. Of course there are always workarounds to solve this!
1. Route Based
The first solution would be to use a route based VPN. When traffic is routed across the IPsec VPN. The next-hop interface in the flow engine then changes from the gr-0/0/0 tunnel interface to the st0 interface and the traffic is correctly encrypted and encapsulated in ESP before being sent over the GRE tunnel.
As mentioned before, my remote side does not support a route based VPN so this does not solve my problem.
2. Looping through the vSRX with a logical tunnel
This is a bit of a far stretched solution that I would not typically recommend using in a production environment, but it works fine and I’ve successfully used this set-up for a few months now.
My goal is that I need another device or virtual device in front of the GRE tunnel, so the next-hop interface changes from the GRE tunnel to something else. I ultimately settled on creating a virtual-router (VRF-lite like) routing-instance on the vSRX. Setting up the GRE tunnel there and looping the traffic back into the default routing-instance using a logical-tunnel.
I will explain the configuration steps involved for this in the next post!

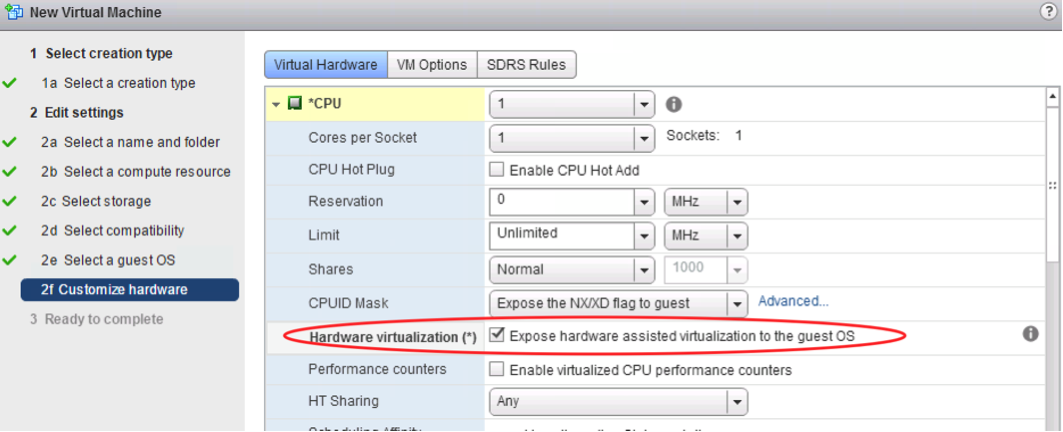
 itecture (released 2008). The technology is ported to the more “Desktop” oriented CPU’s as well, so there is a good chance your notebook supports it as well. Since the Haswell architecture the nested virtualization works even better as Intel now supports VMCS Shadowing for nested VMs, which creates a data structure in memory per VM (and now supports nested VMs as well, which used to be a software effort).
itecture (released 2008). The technology is ported to the more “Desktop” oriented CPU’s as well, so there is a good chance your notebook supports it as well. Since the Haswell architecture the nested virtualization works even better as Intel now supports VMCS Shadowing for nested VMs, which creates a data structure in memory per VM (and now supports nested VMs as well, which used to be a software effort).